
Every organization runs on knowledge that lives in heads, documents, and daily workflows. The knowledge management process is the system that pulls those scattered pieces into something a team can find, trust, and reuse. Read AI was built for the part of this problem that traditional knowledge bases never solved. Documents and wikis only capture what someone took the time to write down. The reasoning behind a decision, the context from a customer call, the back-and-forth in Slack that resolved a thorny tradeoff, those rarely make it into a wiki, and they're the most valuable knowledge an organization owns. A working knowledge management process has to account for both the artifacts and the intelligence behind them. This includes managing enterprise knowledge, critical information, and intellectual capital across the business.
This guide walks through the eight stages of a working knowledge management process, shows where most implementations break down, and explains what to do about it. This process supports knowledge sharing, knowledge transfer, and knowledge creation across the entire organization.
The knowledge management process is the structured cycle organizations use to identify, capture, organize, store, share, apply, and maintain the collective knowledge that keeps the business running. The goal is to deliver the right knowledge to the right person at the right time so decisions get made faster, work doesn't get repeated, and institutional memory survives turnover.
At a high level, the knowledge management process moves knowledge through six functions in a repeating loop: discover what matters, capture it before it disappears, structure it so people can find it, store it where authority is clear, share it where work happens, and review what's no longer true. Effective knowledge management treats this as a living cycle, not a one-time documentation project.
A single project produces meeting recordings, email threads, Slack messages, CRM notes, design files, and shared docs. Important context lives in all of them. Without a knowledge management process, that context stays siloed, and only the person who created it knows where to look.
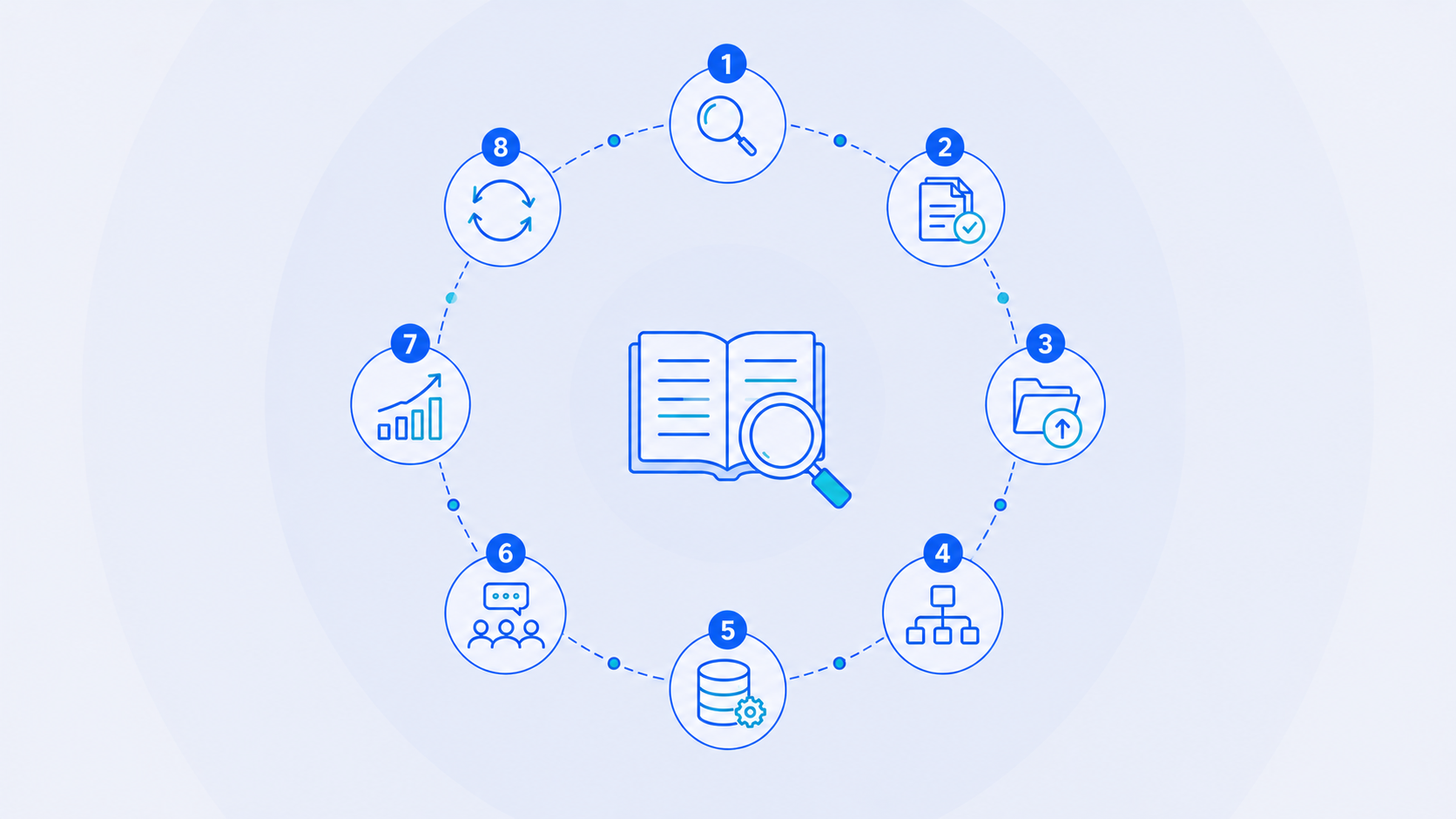
A working knowledge management process has eight stages. Each one maps to an organizational outcome that justifies the effort. Identify connects to risk reduction. Audit connects to coverage. Capture and organize to findability. Store and share connect to daily productivity. Apply and review the connection to compounding value over time.
What follows is each stage with the specific actions that make it work and the failure modes that undo it.
Before you capture anything, decide what's worth capturing. Most teams skip this and end up with a cluttered knowledge base that no one trusts. Start by inventorying existing knowledge sources: shared drives, wikis, recurring meetings, customer-facing playbooks, and the inbox of the person everyone DMs when they have a question. Then assess each source on two axes: value and risk. High-value, high-risk content is anything that drives revenue, prevents costly mistakes, or only exists in one person's head. Prioritize that critical knowledge for capture first. Onboarding documents, decision frameworks for high-stakes calls, customer escalation playbooks, and the reasoning behind your core architecture decisions usually rank highest.
A knowledge audit checks what's already documented against what teams actually need. Run the audit across systems, not just within the wiki. Check whether the answer to your top 50 internal questions exists in writing. Document where it's missing. This is also where you find duplication. Two competing onboarding docs that disagree with each other are worse than one outdated doc, because they erode trust in the whole system. Flag conflicts and assign someone to resolve them.
Capturing explicit knowledge, the kind already written somewhere, is the easy part. Use standardized templates so every captured asset has the same structure. The harder work is capturing tacit knowledge: the why behind a decision, the pattern recognition built over years, the reasoning that doesn't make it into a meeting summary because no one thinks to write it down. This includes both implicit knowledge and institutional knowledge that often goes undocumented.
Schedule structured interviews with subject matter experts to capture tacit knowledge before it walks out the door. Record lessons learned after major events, launches, outages, big wins, and big losses. Read AI's position is that tacit knowledge doesn't get captured because no one remembers to capture it, and that's a process problem AI is built to solve. Our enterprise search, continuously indexes the meetings, emails, messages, and documents where the reasoning lives, so the why behind a decision gets preserved without anyone needing to stop and write it down.
Captured content is useless if no one can find it. A user-centered taxonomy organizes knowledge by how people actually search for it, not by how the org chart is drawn. Apply consistent metadata to every asset: owner, last reviewed date, audience, and related topics. Assign a clear owner to each piece of content so accountability lives somewhere specific. Strong knowledge organization improves access to relevant information and reduces knowledge gaps.
The taxonomy should be navigable in three clicks or fewer. If readers have to drill through six folders to find a process doc, they'll ask a coworker instead, and the system fails on its first real test.
Pick a single system of record for each content type and stick to it. Splitting authoritative content across three tools creates competing sources of truth, and the team learns to trust none of them. Implement version control so people can see when content was last updated and what changed. Build review metadata directly into the asset, next review date, last reviewer, and current status, so stale content surfaces automatically.
The system itself needs to integrate with the tools your team already uses. If captured knowledge can't surface inside the meeting, inbox, or chat where the question came up, it won't get used.
Sharing means embedding knowledge into the workflows where people actually do their jobs. The best knowledge management process pushes proactive updates to the teams that need them: a policy change reaches the support team automatically, not through a forwarded email someone might miss. Search and contextual suggestions surface relevant content where the user already is, whether that's a CRM, an inbox, or a chat thread. This helps teams share knowledge more effectively and improves access to relevant information.
Instead of asking employees to remember to check a wiki, the system brings the right answer to where they're working. Read AI's enterprise search connects meetings, emails, documents, and apps so a question gets answered with sources, not a list of links to sort through.
Knowledge that's never reused isn't really knowledge, it's an archive. Design assets for reuse: modular templates, repeatable frameworks, decision trees that apply across cases. Track reuse metrics. How often is each asset accessed, and does usage correlate with faster resolution times or better outcomes? Collect user feedback on whether the content actually answered the question. This supports better decision-making and improves overall business outcomes and customer satisfaction.
The final stage is where most knowledge management initiatives die quietly. Schedule periodic content reviews by owners: quarterly for high-traffic content, semi-annually for the rest. Archive or retire outdated assets so the search index stays clean. Run retrospectives after major projects, departures, or org changes to capture new critical knowledge before it disappears.
Loss of knowledge is one of the most underappreciated costs in business. When employees leave, get promoted, or change roles, the organization loses what they knew unless the process explicitly captures it first. The classic version: a senior account manager departs, and three weeks later, no one on the renewal call can explain why the customer pushed back on the original contract terms or what was promised on the follow-up. Read AI calls this Insurance of Intelligence: the principle that an organization's most valuable knowledge isn't its documents but the reasoning, decisions, and patterns its people accumulate. A working knowledge management process makes sure that knowledge stays searchable and accessible, even when the people change.
A knowledge management strategy gives the process direction. Without one, teams capture content but can't explain why it matters or what success looks like. Strategy work happens before the first asset gets documented. It should also reflect organizational processes and support continuous learning across teams.
Align knowledge management goals with business objectives. If the company's priority is faster onboarding, the strategy targets the content new hires need in their first 30 days. If the priority is reducing duplicated research, the strategy targets findability. Define measurable success criteria upfront: time-to-answer for support reps, ramp time for new hires, percentage of decisions that reference prior work.
Secure executive sponsorship and resources before the rollout. Knowledge management initiatives that survive without leadership backing are rare. The sponsor doesn't need to manage the program day-to-day, but they need to clear the way when teams resist contributing or when the budget gets cut.
The right tool depends on what already exists. Evaluate integration with your current stack first. A platform that doesn't connect to the meeting tools, email systems, and chat platforms your team uses every day creates a parallel system instead of a connected one. Test search relevance on real queries from real teams, not the demo dataset. Verify security and access controls match your governance requirements, who can see what, who can edit what, and what happens when someone leaves the company.
Read AI takes a different approach. Instead of asking teams to manually contribute content into a separate platform, it indexes the work already happening across meetings, messages, and documents into a connected knowledge graph. Because Read AI sits across your existing stack instead of replacing any part of it, there's no parallel system for the team to learn and no migration to schedule before the process starts paying back.
Read AI is SOC 2 Type 2 certified, GDPR and HIPAA compliant, and does not train on customer data by default.
Knowledge management without ownership is wishful thinking, but the legacy model gets ownership wrong. Most governance frameworks treat knowledge as authored content that needs human review before it goes live. That assumption is what makes traditional KM programs stall. Asking busy people to document their work is the failure mode, not the solution. The most valuable knowledge isn't sitting in a draft waiting for approval. It's already happening in meetings, emails, and chat threads where decisions actually get made.
A working governance model assumes continuous ingestion, not episodic contribution. The system captures knowledge from where work happens, and governance applies to those captured streams. That changes what ownership means. Owners aren't just accountable for files. They're accountable for the reasoning behind decisions, the context that explains why a path was chosen, and the institutional memory that lives in conversations rather than documents. Curators maintain the taxonomy and validate what the system surfaces. Contributors refine and correct, but they don't carry the full burden of authoring everything from scratch.
Governance also has to be a system-and-human hybrid. AI handles capture, tagging, and structuring at a scale humans can't sustain. Humans validate, refine, and decide what's authoritative. Define explicitly what the system auto-generates versus what requires a human review step. The same logic applies to where governance lives. A policy that only governs content inside one repository ignores the reality that knowledge moves across meetings, email, Slack, CRM, and docs. Governance has to operate across the existing stack, not inside a single platform.
The last piece is what governance enables, not just what it controls. A knowledge base that only stores content is a static archive. Governance should define which knowledge can initiate workflows, trigger updates, or push tasks into action through MCP integrations and proactive agents. Measure adoption and usage signals, not just process compliance. Training matters, but workflow integration matters more. If the system surfaces the right answer inside the meeting or message where the question came up, contribution becomes a byproduct of normal work instead of a separate task people have to remember.
Three metrics tell you whether the process is working. Time-to-answer measures how long it takes someone to find the information they need, if it's getting faster, the system is working. Stale-content rate measures the percentage of assets that haven't been reviewed within their target window. If that's growing, the system is decaying. Search success rate measures the percentage of queries that return a useful result. If it's flat or declining while content grows, the taxonomy is breaking down.
Run quarterly reviews of process performance. Check the metrics against your strategy goals. Adjust where the gap between intent and outcome is widest.
AI changes what's possible in knowledge management because it removes the manual step that breaks every traditional system: the requirement that someone remembers to document something. Pilot AI-assisted content suggestions where they have the highest leverage, usually meeting summaries, action item extraction, and answer generation from connected sources. Automate metadata tagging where the AI can do it more consistently than humans can. Validate AI outputs against authoritative sources so the system catches errors before they reach a user.
The goal is AI-first knowledge management, not AI-as-add-on. The reason traditional knowledge management systems go unused isn't that the documentation is bad. It's that finding the documentation requires leaving the work you're doing. AI surfaces relevant knowledge inside the meeting, email, or message where the question came up, eliminating the friction that kills adoption.
Three failures account for most stalled knowledge management programs. Duplicate, conflicting assets erode trust faster than any single bad doc, so detect and merge them aggressively. Lack of employee buy-in usually traces back to incentives. If contributing knowledge takes time but doesn't show up in performance reviews, the system stays empty. Over-documenting low-value knowledge buries the high-value content under noise. Ruthless prioritization beats comprehensive coverage every time.
A working knowledge management process is less about the tool and more about the discipline. The organizations that get compounding value from it are the ones that treat it as infrastructure, maintained, reviewed, and integrated into how work actually happens. A strong knowledge management process turns scattered information into usable knowledge that drives faster decisions, better outcomes, and long-term organizational value.
Get Started with Read AI
The knowledge management process has eight stages: identify critical knowledge, audit existing knowledge to find what's missing, capture both explicit and tacit knowledge, organize and structure assets with metadata, store them in a primary system, share and distribute through workflows, apply and reuse with measurement, and review to retire outdated content. Some frameworks compress these into five or six steps, but the underlying functions are the same.
The strategy defines what knowledge to manage and why. The process defines how to capture, organize, share, and maintain it. Strategy is the direction; process is the execution. A strong process without a strategy produces a tidy archive no one uses. A strong strategy without a process produces ambition that no one acts on.
Explicit knowledge is anything that's already written down or easily documented, such as policies, procedures, and technical specs. Tacit knowledge is the reasoning, intuition, and pattern recognition built through experience. It rarely makes it into a wiki because the person who has it doesn't think to write it down. Capturing tacit knowledge requires structured interviews, retrospectives, or AI tools that index the conversations and decisions where it actually surfaces.
Traditional rollouts take time. A pilot typically runs 60 to 90 days, and a full enterprise rollout takes six to twelve months, with most of the timeline going to professional services and configuration rather than actual knowledge work. Read AI compresses that by orders of magnitude. You can get started in about 20 minutes with no IT setup, which turns a 60-day pilot into a same-day one, and organization-wide rollouts run in weeks instead of quarters.
The three most useful metrics are time-to-answer (how quickly people find what they need), reuse rate (how often captured assets get applied to new work), and stale-content rate (the percentage of assets overdue for review). Read AI's view is that time-to-answer is the metric that matters most, because it's the one users feel every day. When the answer takes more than a few seconds to surface inside the workflow, people stop trusting the system and go back to asking a coworker. Track all three against strategy goals quarterly.


%2C%20Color%3DOriginal.png)

